Blameless post mortem: Ajustes de función en `bootstrapping_tools`
30 Jun 2023 - Mario y Memo
Resumen del incidente
- Detectamos el evento cuando aplicamos el remuestreo por bloques en el reporte. Tendencia poblacional de cormorán orejón en las islas del Noroeste de México y salían las gráficas con ajuste incorrecto.
- Extrajimos código para generar una gráfica de la tendencia población de GUMU igual a la del reporte de cormorán.
Cuando hicimos la gráfica el ajuste estaba desplazado en el tiempo (eje x).
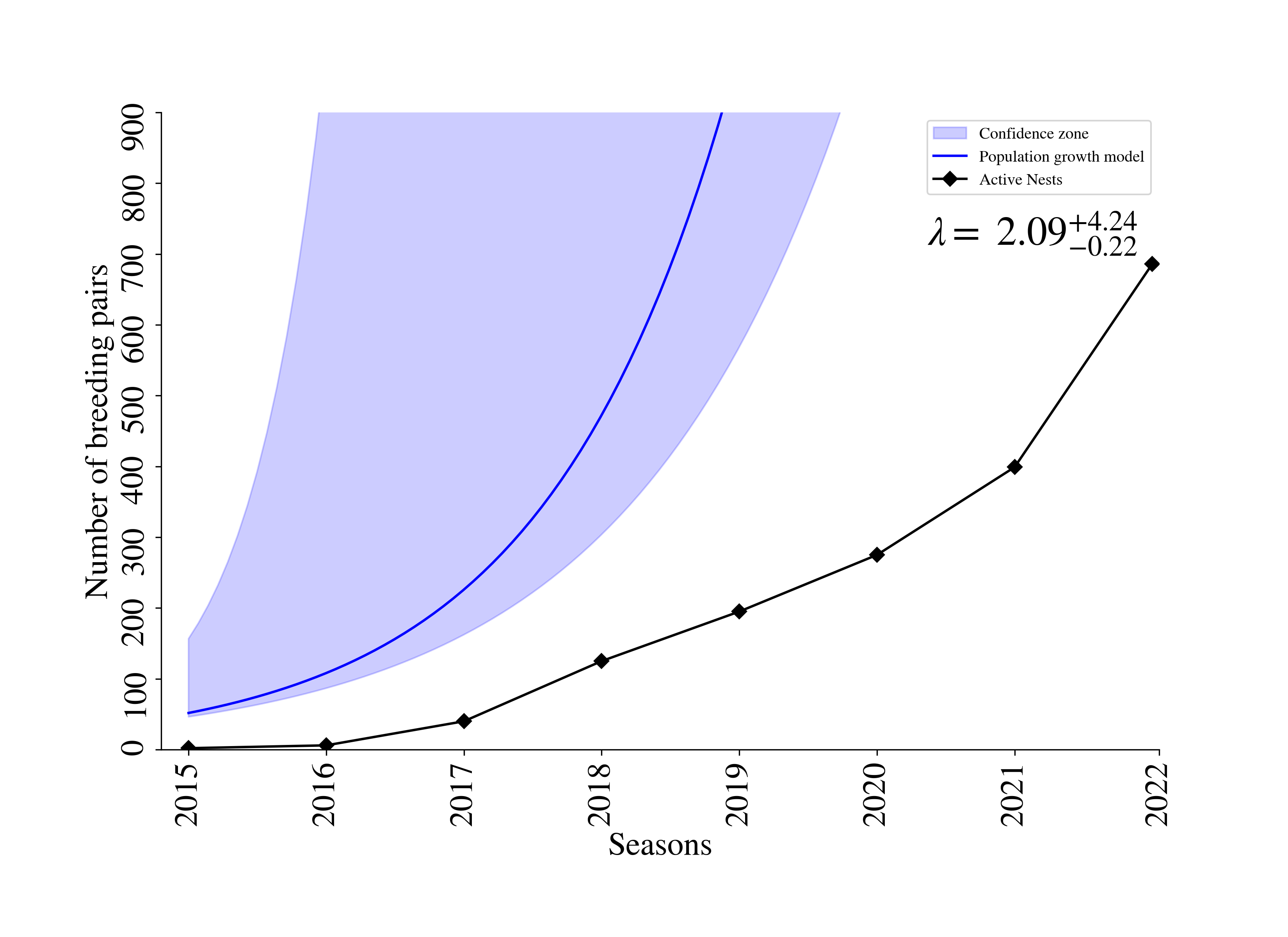
- El bug inició con la implementación de la función
random_resample_data_by_blocksenbootstrapping_tools. - Este incidente va a cambiar los resultados del artículo PLOS ONE. Causó un retraso de una semana en la entrega de la gráfica de GUMU para Yuliana.
¿Qué nos condujo al evento?
- Tenemos mutantes.
- Las pruebas eran limitadas (pocas pruebas y pocos casos límites).
- No pasamos los datos en la forma que los esperaba
lambdas_calculator. - En el repositorio clase 3
cormorant_population_growthlas clases del modeloPopulation_Trend_Modely el graficadoPlotter_Population_Trend_Modelestán acopladas.
Falla
random_resample_data_by_blocks
La función random_resample_data_by_blocks no seleccionaba los últimos bloques.
Los ajustes no tomaban en cuenta los últimos años.
Por ejemplo, para una serie completa de 10 años y bloque de tamaño l = 3 tiene 10 posibles bloques.
Los bloques son: 123, 234, 345, 456, 567, 678, 789, 890, 901 y 012.
Seleccionábamos ceil(10/l) = 4 bloques al azar de los primeros cuatro bloques: 123, 234, 345 y 456.
No podíamos seleccionar los últimos bloques: 567, 678, 789, 890, 901 y 012.
lambdas_calculator
La función lambdas_calculator estaba asumiendo que el primer elemento es el primer año (eje x ordenado).
lambdas_calculator no sabe que los datos están remuestreados en la implementación.
Por ejemplo, consideremos que nuestros bloques remuestreados son: 234, 456, 345 y 234.
Los índices de los años en la serie de tiempo eran 234456345234.
Los índices no les correspondían al tiempo que debían.
El ajuste toma como año inicial el primer elemento del primer bloque de la serie remuestreada.
En este ejemplo el dos se vuelve el año inicial, es decir 0.
Aquí tendremos la serie de tiempo con los años correspondientes al 23456. Así que tendremos años con más peso.
Population_Trend_Model
En Population_Trend_Model desvinculamos las lambdas remuestreadas de su par $N_0$, la población inicial.
Plotter_Population_Trend_Model
En Plotter_Population_Trend_Model el tiempo empieza en 1.
Es decir, graficábamos $N_1$ en $t_0$, $N_2$ en $t_1$ y así sucesivamente.
Este no fue un error crítico pero consumió tiempo para corregir y analizar si era la causa raíz del problema.
Impacto
- Resultados PLOS ONE.
- Gráficas DCCO para Emily.
- Gráfica GUMU para Yuliana.
Detección
Nos dimos cuenta cuando reutilizamos el código de las clases Population_Trend_Model y Plotter_Population_Trend_Model con los datos de GUMU.
El pipeline no nos tronó, así que la detección fue visual. Aquí enlistamos algunas pistas que tuvimos:
- El revisor del PLOS nos sugirió que hiciéramos el ajuste manual.
- Al ver el resultado de las gráficas notamos que el ajuste se veía raro.
- Tuvimos la detección de parte de Emily y no escuchamos.
- En cada entrega que hicimos, no nos gustaban las figuras.
- Cambiamos a $l=2$ y $l=3$ algunas mejoraban y otras empeoraban.
- Hicimos un ajuste a los datos crudos y era evidentemente mejor al ajuste bootstrap.
¿Hubiéramos podido hacer una prueba automática o lo debe hacer un humano (checklist)? ¿Cuándo decidimos hacer una inspección?
Respuesta
- Generamos la gráfica de GUMU y notamos que no se veía bien el ajuste.
- Exploramos los repositorios involucrados y detectamos las posibles causas.
- Cazamos mutantes y agregamos pruebas para comprobar nuestras suposiciones.
- Corregimos la dependencia circular entre los repositorios
lambdas_aves_marinas,population_trenybootstrapping_toolscomo lo sugiere el tío Bob .
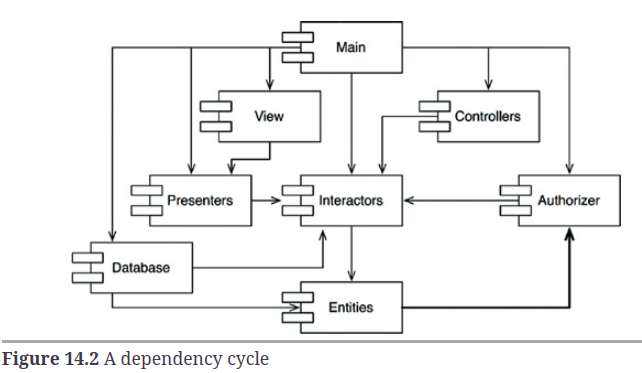
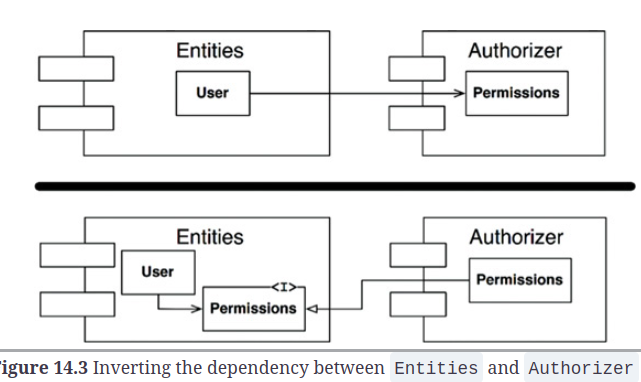
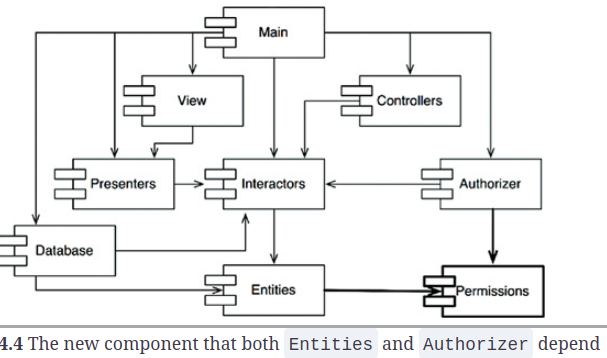
Recuperación
Hicimos pruebas manuales. Quitamos la semilla y notamos que no seleccionábamos los últimos bloques. Agregamos una prueba que tronara debido al bug. Corregimos el bug.
Reducción del tiempo de recuperación
Hacer el ajuste a los datos crudos nos hubiera ayudado a descartar el método de graficado. Los datos sintéticos nos hubiera ayudado a tomar de decisión de que los resultados estaban mal.
Línea de tiempo
2020-01-21 Usamos calcula_lambda sin remuestrear.
2021-06-06 Nos trajimos lambda_calculator de otro repositorio. bootstrap_from_time_series le pasa los datos remuestreados ordenados a lambda_calculator pero el remuestreo podría haber quitado el primer año.
2022-06-10. Aquí agregamos la funcionalidad de _get_labels.
2022-06-10. Extrajimos la función _get_labels con pruebas tronando.
2022-06-23. Usamos _get_labels en el remuestreo.
2022-07-20 Implementamos random_resample_by_blocks. Aquí le pasamos los datos remuestreados y desordenados a lambda_calculator.
2023-06-28 Regresamos implementación de lambda_calculator para obtener la población inicial. Nos damos cuenta que el error está en niveles más abajo.
Cinco por qué
-
Los datos que ajustábamos no contenían todos los datos originales, faltaban los últimos datos. El ajuste de la gráfica no se ve bien porque la
N_0y lalambdaestán desvinculadas. Además el modelo no empieza ent=0y el ajuste está desplazado. -
Faltaban los últimos datos, porque solo seleccionábamos los primeros
ceil(n/l)bloques. LaN_0y lalambdaestán desvinculadas porque solo le pasamos las lambdas remuestreadas sin sus correspondientesN_0. El modelo no empieza ent=0porque no obtenemos el dominio de los datos originales. El ajuste está desplazado porque metemos los datos remuestreados de manera incorrecta. -
Solo los primero bloques porque nos confundimos la serie debía formarse por 4 bloques de los 10 posibles. Solo le pasamos las lambdas remuestreadas sin sus correspondientes
N_0porque enbootstrapping_from_time_seriessolo guardamos laslambdas. No obtenemos el dominio de los datos originales porque reciclamos la variable en el graficado. Metemos los datos remuestreados de manera incorrecta porque no aseguramos que están ordenados y con el primer año de los datos originales. -
Nos confundimos porque tuvimos malas prácticas: no probamos los límites, nombres mejorables y cambios muy grandes (extrajimos una función y cambiamos las pruebas). En
bootstrapping_from_time_seriessolo guardamos laslambdasporque es el resultado que reportamos. Reciclamos la variable en el graficado porque las clases comparten variables. No aseguramos que los datos remuestreados estén ordenados y con el primer año de los datos originales porque no sabíamos quelambda_calculatorlos necesitaba así. -
Tuvimos malas prácticas por inexperiencia en el TDD. Las clases comparten variables porque rompemos con la encapsulación. No sabíamos y tampoco las pruebas que
lambda_calculatornecesitaba los datos ordenados y/o con el primer año porque las pruebas y documentación no eran suficientes.
Causa raíz
- Al construir la función
random_resample_data_by_blocksno probamos los casos límites. - En el evento del 2022-06-10, señalado en la línea de tiempo, la extracción de la función la hicimos mientras había una prueba tronando.
- Al trabajar con código reliquia no agregamos pruebas suficientes que describieran el comportamiento de las funciones.
Lecciones aprendidas y cosas ganadas
- Discutimos sobre arquitectura de software: dependencia cíclica, interfaces, componentes, inversión de dependencia.
- Los datos sintéticos nos hubiera ayudado a tomar la decisión de que los resultados estaban mal.
- Aceptamos que había un problema y lo corregimos.
- Usamos esta plantilla.
Acciones correctivas
- Escuchar la retroalimentación proporcionada por los externos. No descartar las observaciones sin evidencia.
- Los phonies
red,greenyrefactornos han ayudado a ser más estrictos en el TDD. - Tener un conjunto de pruebas más amplio.